در پستهای قبلی با یادگیری با نظارت و بدون نظارت آشنا شدیم.
خوشه بندی یا Clustering از روشهای داده کاوی است که از یادگیری بدون نظارت استفاده می کند. در واقع خوشه بندی بدون داشتن یک مثال آموزشی و بدون هر گونه ناظر سعی در پیدا کردن شباهتهای موجود در داده ها دارد به گونه ای که موارد شبیه بهم در یک خوشه قرار می گیرند و موارد داخل دو خوشه متفاوت با هم تفاوت فاحشی دارند. شباهت بین دو مورد بر اساس فاصله اقلیدسی بین آن دو سنجیده می شود به گونه ای که هر چه فاصله بین دو شی کمتر باشد، شباهت بین دو مورد بیشتر و هر چه فاصله بین دو مورد از هم بیشتر باشد، شباهت کمتر است.
مثال برای خوشه بندی، در نظر گرفتن جاندارن در دو خوشه پستاندار و خزنده است. در خوشه پستانداران، انسان، پلنگ، فیل، و غیره قرار می گیرند. از سوی دیگر، خوشه خزنده شامل مار، مارمولک، اژدها کامودو و غیره می شود.
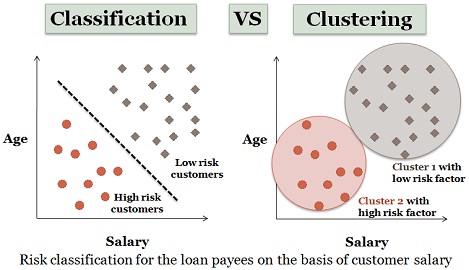
طبقه بندی، فرایند دسته بندی داده ها به کمک برچسب کلاس هاست.در طبقه بندی یا Classification نیاز به داده های آموزشی هست در حالی که در خوشه بندی نیاز به یادگیری و داده های آموزشی نیست.
به عنوان مثالی از طبقه بندی، فرم درخواست وام را در بانکها در نظر بگیرید. مشتریان تکمیل کننده این فرمها را می توان طبق سن و دستمزدشان، به عنوان مشتری بدون ریسک یا پرریسک دسته بندی نمود. به این نوع فعالیت، یادگیری تحت نظارت گفته می شود. مدل ساخته شده می تواند برای طبقه بندی داده های جدید مورد استفاده قرار گیرد. گام یادگیری می تواند با استفاده از مجموعه داده های آموزشی تعریف شده، اجرا شود. مدل تولیدی می تواند در قالب یک درخت تصمیم گیری یا مجموعه ای از قوانین باشد.
مرتضی علیاری
1397/1/27

 مینا
مینا
