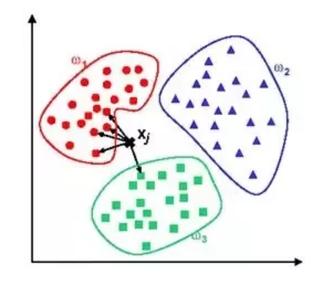
در پستهای قبلی در مورد تفاوت میان طبقه بندی و خوشه بندی بحث کردیم. در مورد سوال این پست نیز اولین پاسخی که می توان داد این است که الگوریتم K نزدیکترین همسایگی (KNN) یک الگوریتم طبقه بندی و الگوریتم k-means یک الگوریتم خوشه بندی است. منطق الگوریتم KNN به زبان ساده این است که اگر شما شبیه به همسایگانتان باشید، آنگاه شما یکی از آنها خواهید بود. یا اگر سیب شباهت بیشتری به موز، پرتقال و ملون (میوه) نسبت به یک میمون، گربه یا موش (حیوان) دارد، آنگاه به احتمال قوی سیب یک میوه است. در ادامه مثالی آورده شده است. فرض کنید سه کلاس داریم و هدف پیدا کردن کلاس مناسب یرای مثال ناشناخته xj است. بعبارت دیگر می خواهیم بدانیم برای مثال ناشناخته xj ، کدام برچسب کلاس مناسبتر است. در این مورد از فاصله اقلیدسی و k=5 همسایه استفاده کرده ایم. از میان 5 تا از نزدیکترین همسایه ها، 4 تا متعلق به w1 و یکی متعلق بهw3 است بنابراین xj به w1 ، کلاس غالب، تخصیص داده خواهد شد.
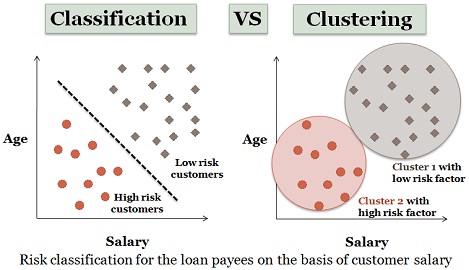
در مورد K-means هم که شما باید با داشتن تعدادی داده، آنها را در K خوشه، خوشه بندی کنید. روش K-means متعلق به خانواده الگوریتمهای مرکز متحرک است به این معنا که مرکز خوشه در هر تکرار به آهستگی به سمت مینیمم کردن تابع هدف پیشروی می کند. در شکل زیر شما با یک حدس اولیه برای میانگینهای خوشه های m1 و m2 شروع می کنید و از این میانگینها برای گروه بندی هدف هایتان استفاده می کنید، سپس میانگینها را بروز می کنید و دوباره گروه بندی می کنید و این کار را تا جایی ادامه می دهید که میانگینهای m1 و m2 تغییر یا حرکت نکنند یا اینکه عملیات تکرار را تا دستیابی به یک حد آستانه (بعنوان مثال تعداد تکرارها) ادامه می دهید.